你的浏览器禁用了JavaScript, 请开启后刷新浏览器获得更好的体验!
首页
热门
推荐
精选
登录
|
注册
python获取免费代理
立即下载
用AI写一个
金额:
2
元
支付方式:
友情提醒:源码购买后不支持退换货
立即支付
我要免费下载
发布时间:2018-04-17
2人
|
浏览:3251次
|
收藏
|
分享
技术:python3.6.1 + requests + BeautifulSoup4
运行环境:python3.6.1 + requests + BeautifulSoup4
概述
获取免费提供代理的几个网站上近期可用的代理, 保存格式目前为txt。
详细
##一、需求 在使用爬虫抓取页面时有时会封ip,这时需要使用代理,所以需要使用代理来规避封ip带来的麻烦,需求量不大的话使用免费的代理即可,这个小程序就是来干这个的。 ##二、程序说明 * 程序结构? 不存在的!整个小程序都在一个文件内存储 * 思路 * 获取几个免费代理网站的所有代理 根据几个网站的不同需要使用不同的数据获取方式,比如快代理: ```python def proxy_kuai(self): """抓取快代理中的免费代理""" base_url = 'https://www.kuaidaili.com/free/inha/{}/' for i in range(1, 5): time.sleep(1) res = requests.get(base_url.format(i), headers=self.headers) soup = BeautifulSoup(res.text, 'lxml') trs = soup.find_all('tr') for tr in trs[1:]: tds = tr.find_all('td') self.queue.put({str(tds[3].text).lower(): str(tds[0].text) + ':' + str(tds[1].text)}) ``` * 上述代码中最后将结果放入队列中,因为之后要用多线程来进行验证,所以使用了python自带的queue队列 > 采集代理的网站包括如几个: http://checkip.amazonaws.com http://www.xicidaili.com https://www.kuaidaili.com/free http://www.ip3366.net http://www.data5u.com/free * 最后该验证获取的代理哪些可用,我这边是向[http://checkip.amazonaws.com](http://checkip.amazonaws.com "http://checkip.amazonaws.com")来验证,通过`requests.get(url, proxies=proxies, timeout=2.01)`来验证,如果是4xx或者5xx的响应状态,get函数会报错,所以使用try-except来捕获异常,完成自己的目标。 * 验证通过的代理可以存储为自己想要的格式,这里使用的是txt * 部分代码演示 ```python def run(self): """ 进行验证并且存储到给定的文件中去 """ start_ips = time.time() print('------开始获取所有免费代理地址-------') self.get_ips() end_ips = time.time() print('------获取结束, 总耗时:{:.2f}s-------'.format(end_ips - start_ips)) print('------开始验证可用代理-------') start_verf = time.time() threads = [] while not self.queue.empty(): for thread in threads: if not thread.is_alive(): # 移除停止活动的线程 threads.remove(thread) while len(threads) < self.max_threads: porxy = self.queue.get() thread = threading.Thread(target=self.go_verify, args=(porxy,)) thread.setDaemon(True) thread.start() threads.append(thread) end_verf = time.time() print('------验证结束,总耗时:{:.2f}s-------'.format(end_verf - start_verf)) with open('http.txt', 'w') as f: for proxy in self.http: f.write(proxy['http'] + '\n') with open('https.txt', 'w') as f: for proxy in self.https: f.write(proxy['https'] + '\n') print('------存储完毕,存储地址为:{} 以及 {}------' .format('http.txt', 'https.txt')) ``` ##三、效果图展示 > 运行状态 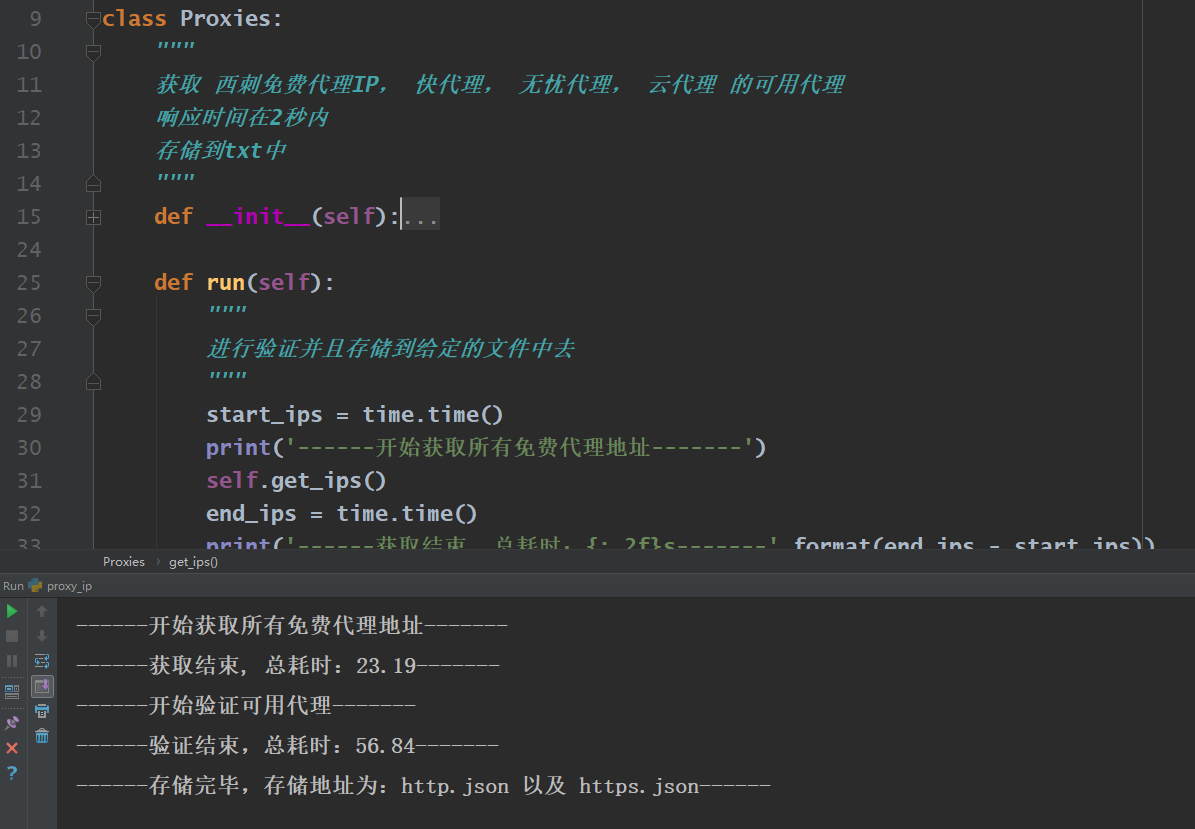 > 运行结果 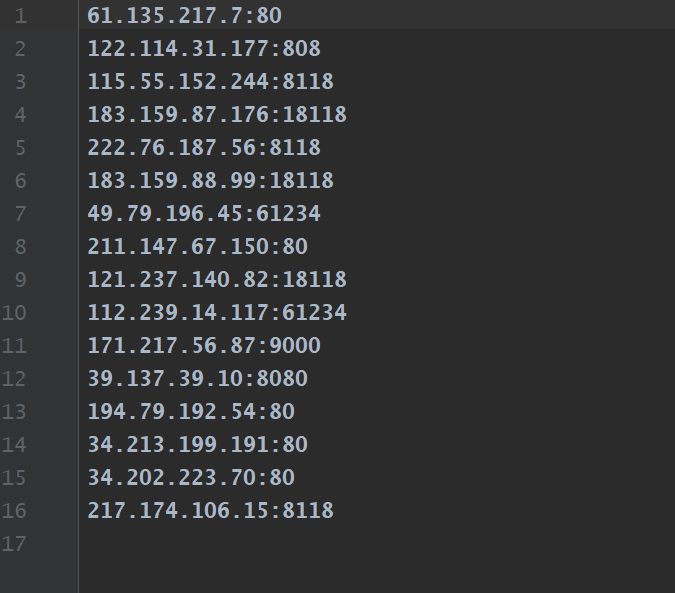 ##四、项目源码结构图 本项目只有一个源码文件 
本实例支付的费用只是购买源码的费用,如有疑问欢迎在文末留言交流,如需作者在线代码指导、定制等,在作者开启付费服务后,可以点击“购买服务”进行实时联系,请知悉,谢谢
感谢
1
手机上随时阅读、收藏该文章 ?请扫下方二维码
相似例子推荐
评论
作者
Ggzzhh
4
例子数量
260
帮助
31
感谢
评分详细
可运行:
4.5
分
代码质量:
4.5
分
文章描述详细:
4.5
分
代码注释:
4.5
分
综合:
4.5
分
作者例子
基于Python-Flask实现的网站例子
使用scrapy进行12306车票查询
python获取免费代理
基于redis的简易分布式爬虫框架





