你的浏览器禁用了JavaScript, 请开启后刷新浏览器获得更好的体验!
首页
热门
推荐
精选
登录
|
注册
Python实现抖音各类型数据可视化
立即下载
用AI写一个
金额:
10
元
支付方式:
友情提醒:源码购买后不支持退换货
立即支付
我要免费下载
发布时间:2021-12-19
2人
|
浏览:3488次
|
收藏
|
分享
技术:python3.9.7+pyecharts1.9.0+PIL6.0.0
运行环境:python3.9.7+pyecharts1.9.0+PIL6.0.0
概述
python利用pyecharts+PIL两个模块对抖音各类型数据进行一个数据可视化!
详细
准备工作 == 做数据可视化,首先得有数据!我利用爬虫爬下来一些数据,咱先瞅瞅 -- 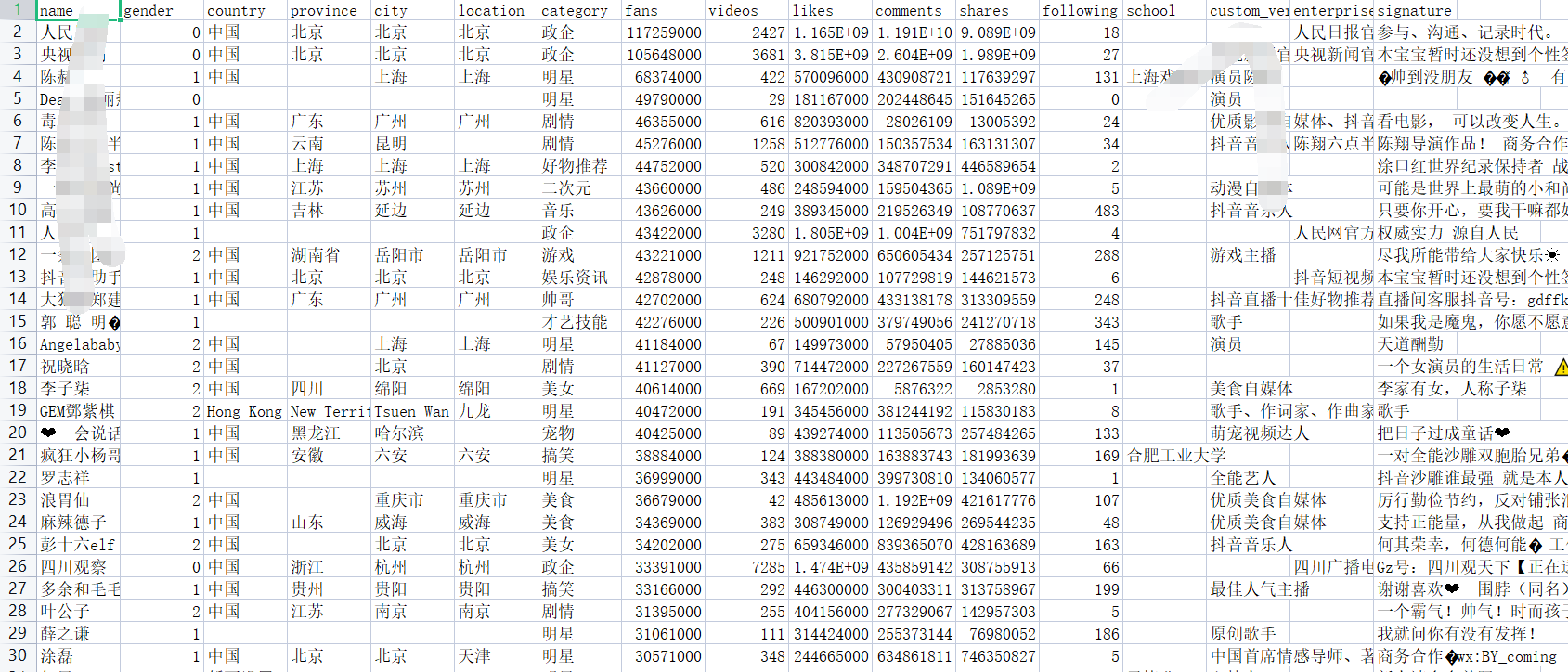 有了数据,那就可以开始敲了!先pip install命令下载我们需要的第三方库pyecharts+PIL -- 一、先导入模块 -- ```python import pandas as pd import numpy as np from pyecharts.charts import Pie, Bar, TreeMap, Map, Geo from pyecharts import options as opts from PIL import Image ``` 整个程序部分代码展示 == 二、第一步我们先把数据导进去吧 -- ```python df = pd.read_csv('file/douyin.csv', header=0, encoding='utf-8-sig') ``` 三、修改一下数值、在根据性别分组进行计数 -- ```python # 修改数值 df.loc[df.gender == '0', 'gender'] = '未知' df.loc[df.gender == '1', 'gender'] = '男性' df.loc[df.gender == '2', 'gender'] = '女性' # 根据性别分组 gender_message = df.groupby(['gender']) # 对分组后的结果进行计数 gender_com = gender_message['gender'].agg(['count']) gender_com.reset_index(inplace=True) ``` 四、添加数据,设置半径 -- ```python pie.add("", [list(z) for z in zip(attr, v1)], radius=["40%", "75%"]) ``` 五、设置全局配置项,标题、图例、工具箱(下载图片) -- ```python pie.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V性别分布情况", pos_left="center"), legend_opts=opts.LegendOpts(orient="vertical", pos_left="left"), toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}})) ``` 六、设置系列配置项,标签样式 ```python pie.set_series_opts(label_opts=opts.LabelOpts(is_show=True, formatter="{b}:{d}%")) ``` 写到这里,第一个类型就写完了,先看看这个运行效果吧! -- 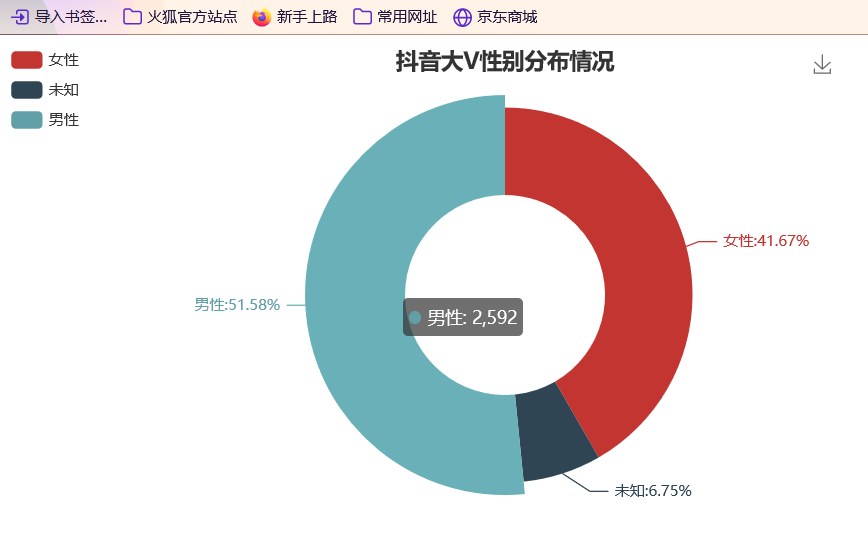 是不是有一点那种成就感的感觉!哈哈哈,好了,咱先把代码全部敲完!然后在看看运行效果吧! == 七、第二种类型可视化,先获取TOP10的数据 -- ```python attr = df['name'][0:10] v1 = [float('%.1f' % (float(i) / 100000000)) for i in df['likes'][0:10]] ``` 八、设置全局配置项,标题、工具箱(下载图片)、y轴分割线 -- ```python bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V点赞数TOP10(亿)", pos_left="center", pos_top="18"), toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}), xaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True))) ``` 九、设置系列配置项,标签样式 -- ```python bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="right", color="black")) bar.reversal_axis() bar.render("抖音大V点赞数TOP10(亿).html") ``` 第二类型的就写完了,运行效果等我们把代码写完,一起发在下面给你们看哈 -- 十、第三种我们先将数据分段 -- ```python Bins = [0, 1000000, 5000000, 10000000, 25000000, 50000000, 100000000, 5000000000] Labels = ['0-100', '100-500', '500-1000', '1000-2500', '2500-5000', '5000-10000', '10000以上'] len_stage = pd.cut(df['likes'], bins=Bins, labels=Labels).value_counts().sort_index() ``` 十 一、获取数据 -- ```python attr = len_stage.index.tolist() v1 = len_stage.values.tolist() ``` 十二、生成柱状图 -- ```python bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V点赞数分布情况(万)", pos_left="center", pos_top="18"), toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}), yaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True))) bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="top", color="black")) bar.render("抖音大V点赞数分布情况(万).html") ``` 这第三种就这样写完了,现在我们看看第四种,其实第四 五 六 七种方式都一样,我就不一个一个列举了,我就统一列举哈 -- 十三、第四 五 六 七种方式一样主要分这三部 -- 1、将数据分段 -- 2、获取数据 -- 3、生成图形 -- 来吧,上代码 -- 第四种类型 -- ```python #将数据分段 df = df.sort_values('fans', ascending=False) attr = df['name'][0:10] #获取数据 v1 = ['%.1f' % (float(i) / 10000) for i in df['fans'][0:10]] #生成图形 bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V粉丝数TOP10(万)", pos_left="center", pos_top="18"), toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}), xaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True))) bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="right", color="black")) bar.reversal_axis() bar.render("抖音大V粉丝数TOP10(万).html") ``` 第五种类型 -- ```python Bins = [0, 1500000, 2000000, 5000000, 10000000, 25000000, 200000000] Labels = ['0-150', '150-200', '200-500', '500-1000', '1000-2500', '5000以上'] len_stage = pd.cut(df['fans'], bins=Bins, labels=Labels).value_counts().sort_index() attr = len_stage.index.tolist() v1 = len_stage.values.tolist() bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V粉丝数分布情况(万)", pos_left="center", pos_top="18"), toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}), yaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True))) bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="top", color="black")) bar.render("抖音大V粉丝数分布情况(万).html") ``` 第六种类型 -- ```python attr = df['name'][0:10] v1 = ['%.1f' % (float(i) / 100000000) for i in df['shares'][0:10]] bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V分享数TOP10(亿)", pos_left="center", pos_top="18"), toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}), xaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True))) bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="right", color="black")) bar.reversal_axis() bar.render("抖音大V分享数TOP10(亿).html") ``` 第七种类型 -- ```python df = df.sort_values('shares', ascending=False) attr = df['name'][0:10] v1 = ['%.1f' % (float(i) / 100000000) for i in df['shares'][0:10]] bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V分享数TOP10(亿)", pos_left="center", pos_top="18"), toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}), xaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True))) bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="right", color="black")) bar.reversal_axis() bar.render("抖音大V分享数TOP10(亿).html") ``` 这几种比较简单原理都一样,咱在看看第八种的 -- 十四、分组求和 -- ```python likes_type_message = df.groupby(['category']) likes_type_com = likes_type_message['likes'].agg(['sum']) likes_type_com.reset_index(inplace=True) ``` 十五、处理数据 -- ```python dom = [{'name': name, 'value': num} for name, num in zip(likes_type_com['category'], likes_type_com['sum'])] ``` 十六、设置全局配置项,标题、工具箱(下载图片) -- ```python .set_global_opts(title_opts=opts.TitleOpts(title="各类型抖音大V点赞数汇总图", pos_left="center", pos_top="5"), toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}), legend_opts=opts.LegendOpts(is_show=False)) ) treemap.render("各类型抖音大V点赞数汇总图.html") ``` 第八种类型就敲完了,全部敲完在看看效果现在敲第九种 -- 十七、第九种也是跟第八种一样的,直接上代码 -- ```python fans_type_message = df.groupby(['category']) fans_type_com = fans_type_message['fans'].agg(['sum']) fans_type_com.reset_index(inplace=True) for name, num in zip(fans_type_com['category'], fans_type_com['sum']): data = {} data['name'] = name data['value'] = num dom.append(data) treemap.set_global_opts(title_opts=opts.TitleOpts(title="各类型抖音大V粉丝数汇总图", pos_left="center", pos_top="5"), toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}), legend_opts=opts.LegendOpts(is_show=False)) treemap.set_series_opts(treemapbreadcrumb_opts=opts.TreeMapBreadcrumbOpts(is_show=False)) treemap.render("各类型抖音大V粉丝数汇总图.html") ``` 说实话,这样速度慢了一点,我直接把代码注释写在代码里面,大家可以参考学习一下 == 第十种类型 -- ```python # 计算单个视频平均点赞数 df.eval('result = likes/(videos*10000)', inplace=True) df['result'] = df['result'].round(decimals=1) df = df.sort_values('result', ascending=False) # 添加数据 bar.add_xaxis(list(reversed(attr.tolist()))) bar.add_yaxis("", list(reversed(v1))) # 设置全局配置项,标题、工具箱(下载图片)、y轴分割线 bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V平均视频点赞数TOP10(万)", pos_left="center", pos_top="18"), toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}), xaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True))) # 设置系列配置项 bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="right", color="black")) # 翻转xy轴 bar.reversal_axis() bar.render("抖音大V平均视频点赞数TOP10(万).html") ``` 第十一中类型 -- ```python # 筛选数据 df = df[df["country"] == "中国"] df1 = df.copy() # 数据替换 df1["province"] = df1["province"].str.replace("省", "").str.replace("壮族自治区", "").str.replace("维吾尔自治区", "").str.replace("自治区", "") # 分组计数 df_num = df1.groupby("province")["province"].agg(count="count") df_province = df_num.index.values.tolist() df_count = df_num["count"].values.tolist() # 中国地图 map.add("", [list(z) for z in zip(df_province, df_count)], "china") # 设置全局配置项,标题、工具箱(下载图片)、颜色图例 map.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V省份分布情况", pos_left="center", pos_top="0"), toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}), # 设置数值范围0-600,is_piecewise标签值连续 visualmap_opts=opts.VisualMapOpts(max_=600, is_piecewise=False)) map.render("抖音大V省份分布情况.html") ``` 第十二种类型 -- ```python df1 = df[df["country"] == "中国"] df1 = df1.copy() df1["city"] = df1["city"].str.replace("市", "") df_num = df1.groupby("city")["city"].agg(count="count").reset_index().sort_values(by="count", ascending=False) df_city = df_num[:10]["city"].values.tolist() df_count = df_num[:10]["count"].values.tolist() bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V城市分布TOP10", pos_left="center", pos_top="18"), toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}), yaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True))) bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="top", color="black")) bar.render("抖音大V城市分布TOP10.html") ``` 第十三种类型 -- ```python df1 = df[(df["school"] != "") & (df["school"] != "已毕业") & (df["school"] != "未知")] df1 = df1.copy() df_num = df1.groupby("school")["school"].agg(count="count").reset_index().sort_values(by="count", ascending=False) df_school = df_num[:10]["school"].values.tolist() df_count = df_num[:10]["count"].values.tolist() # 初始化配置 bar = Bar(init_opts=opts.InitOpts(width="1200px", height="400px")) bar.add_xaxis(df_school) bar.add_yaxis("", df_count) bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V毕业学校TOP10", pos_left="center", pos_top="18"), toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}), yaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True))) bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="top", color="black")) bar.render("抖音大V毕业学校TOP10.html") ``` 这样我们全部的抖音类型数据可视化程序就写完了,看看效果吧! -- 项目结构 ==  运行结果 == 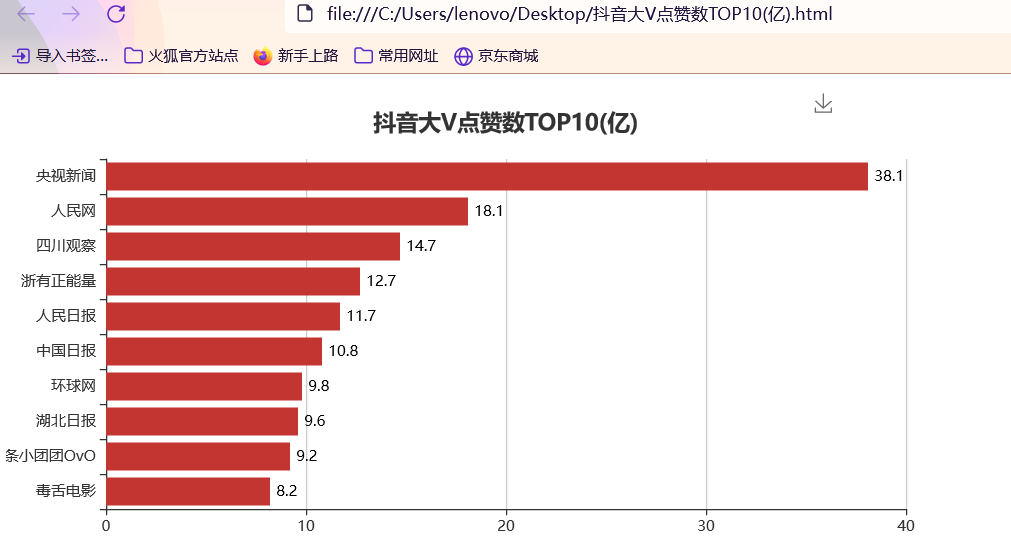 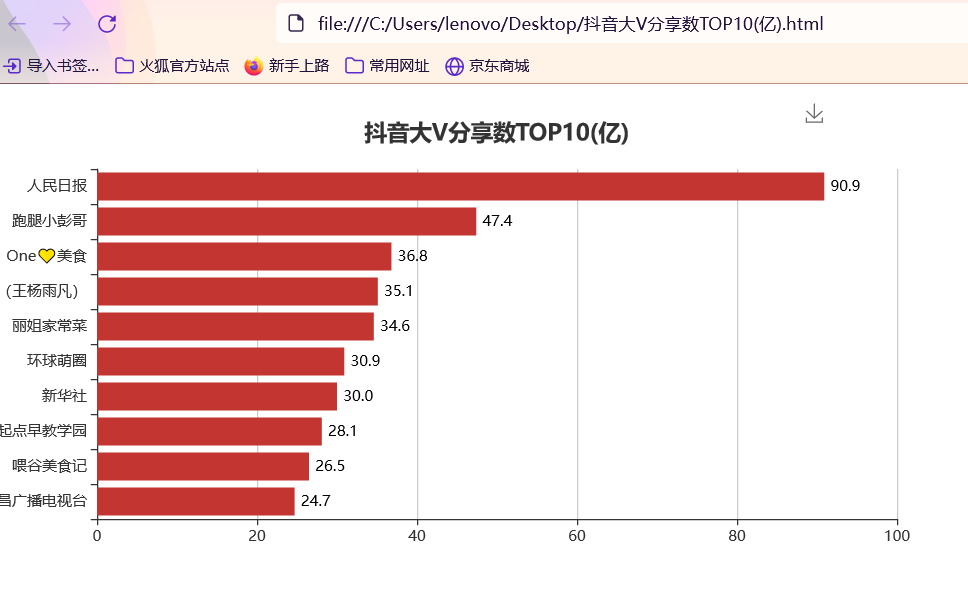 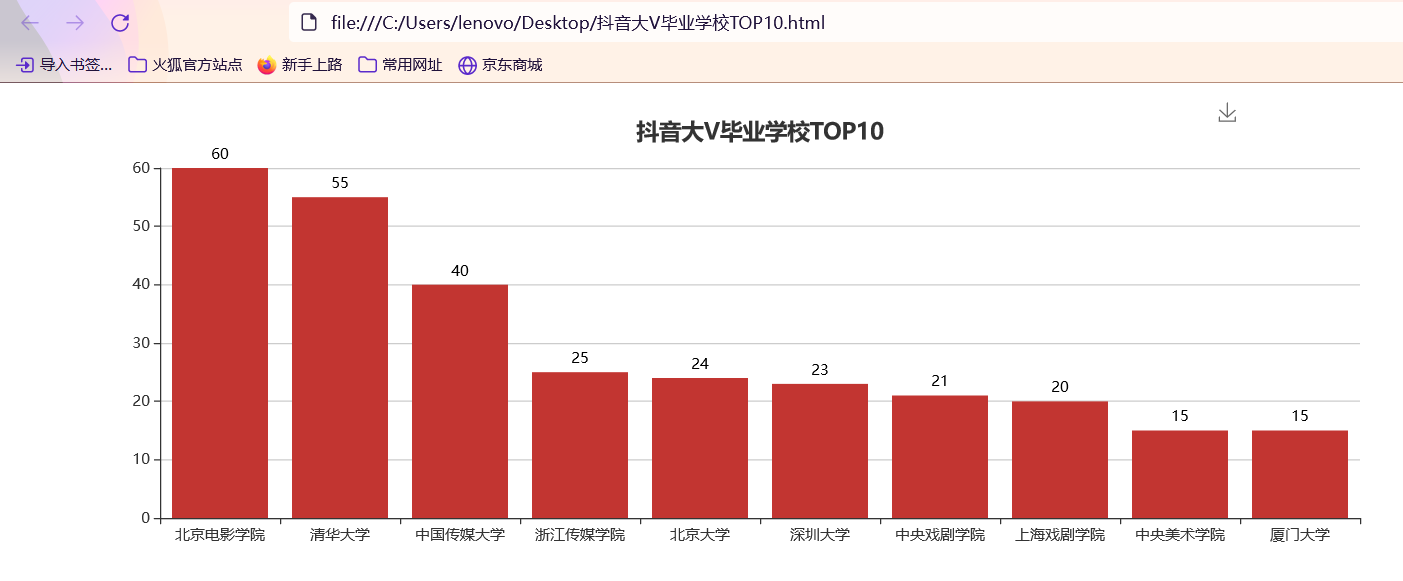 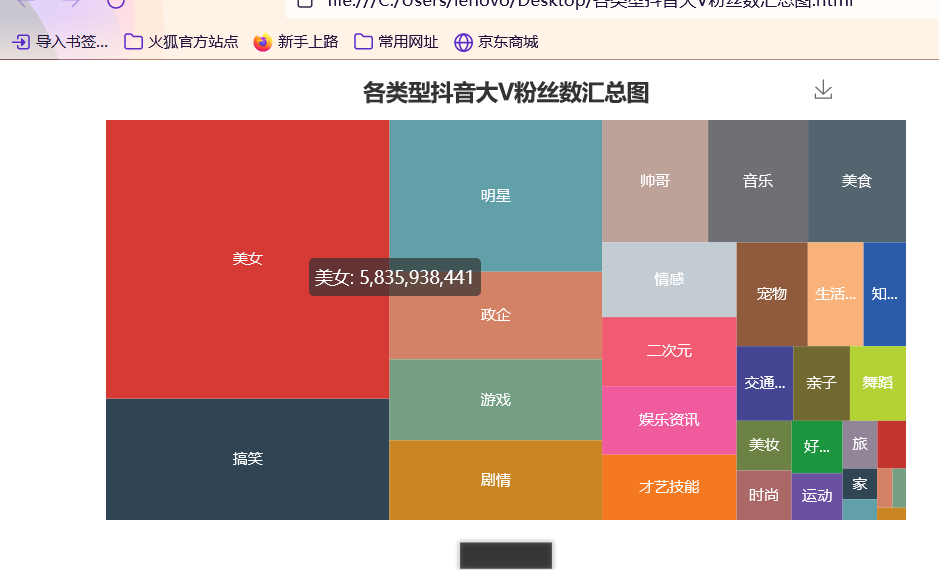 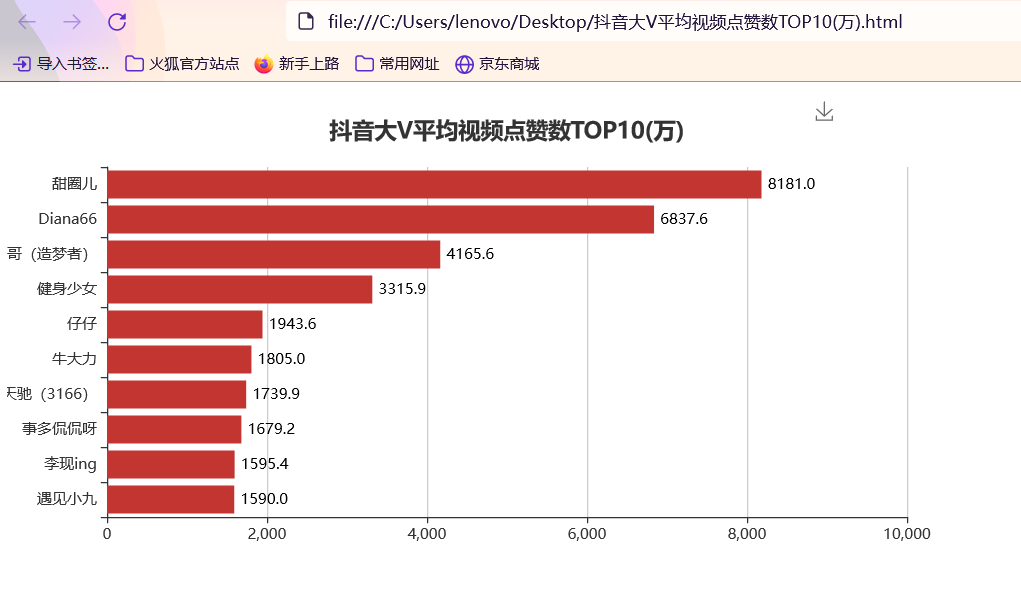 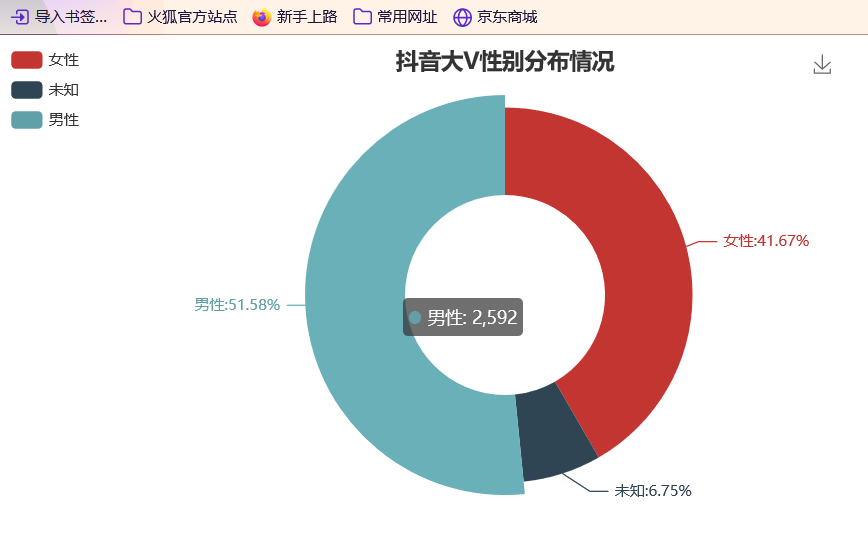 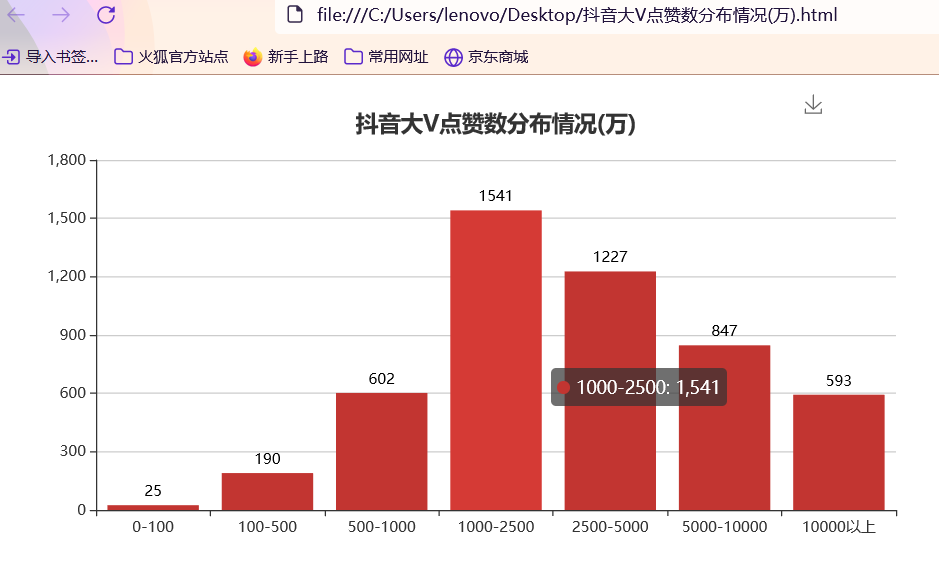 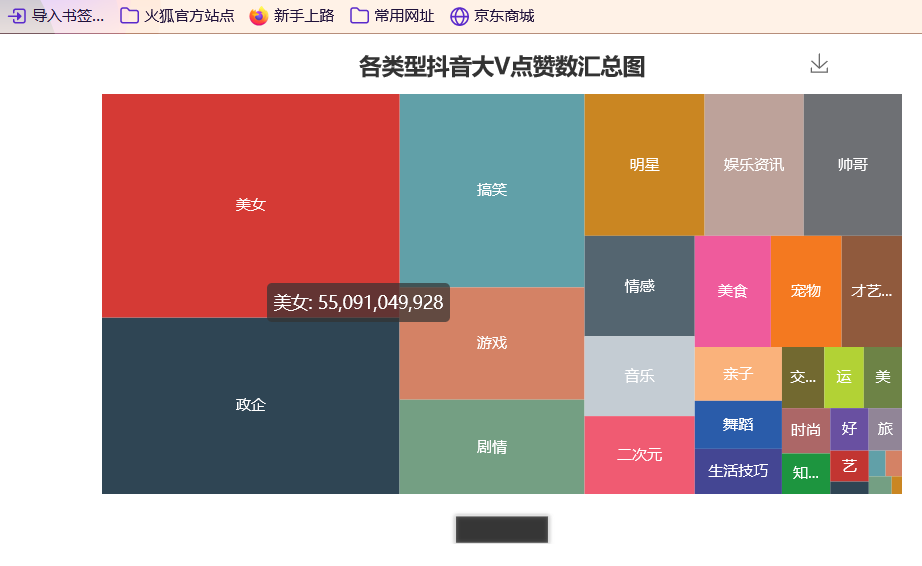 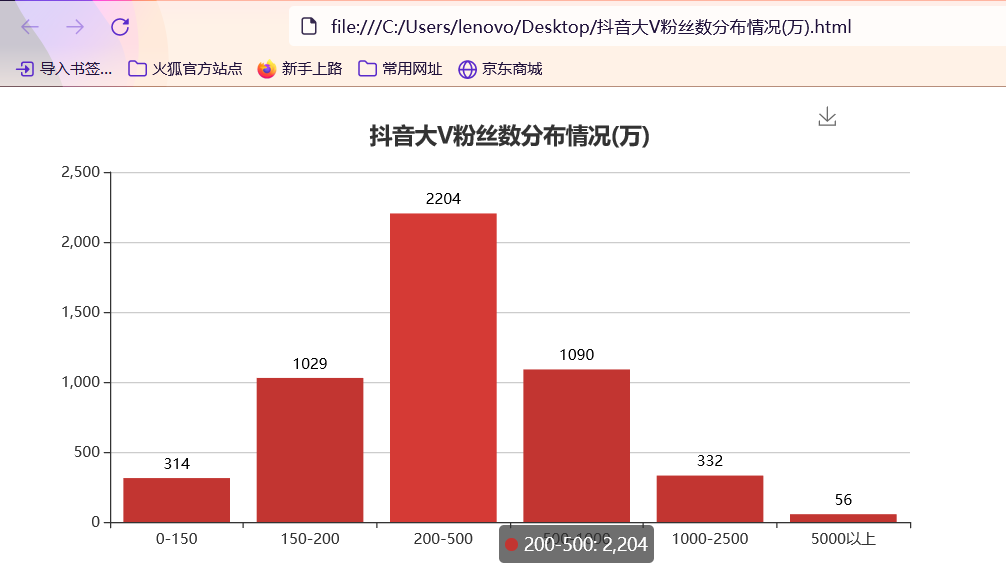 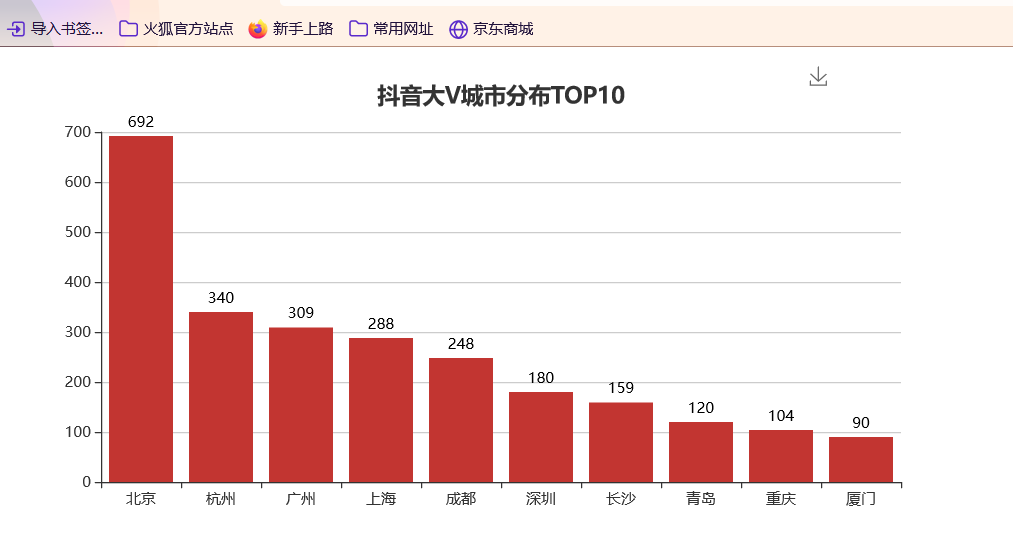 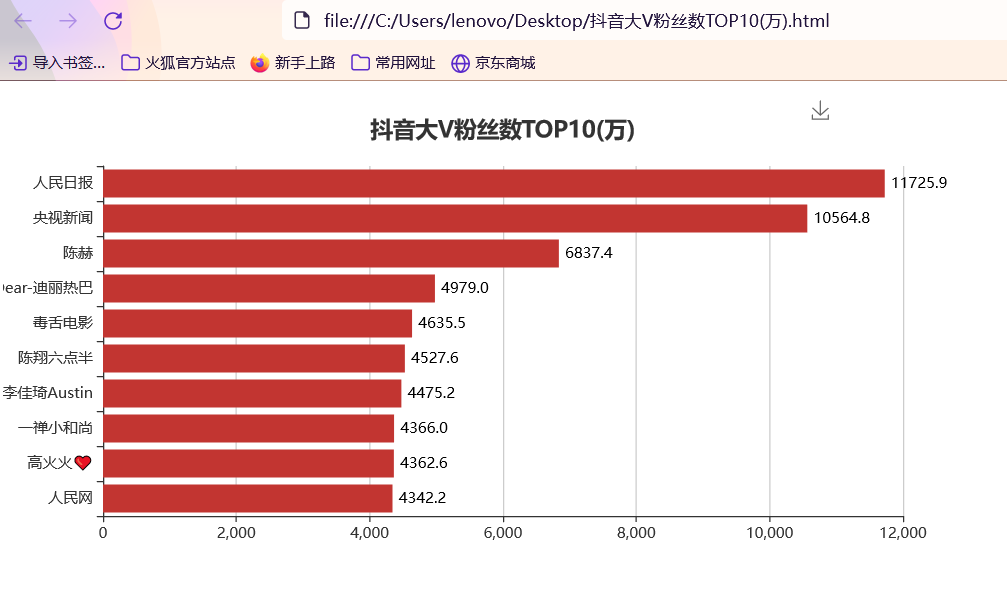 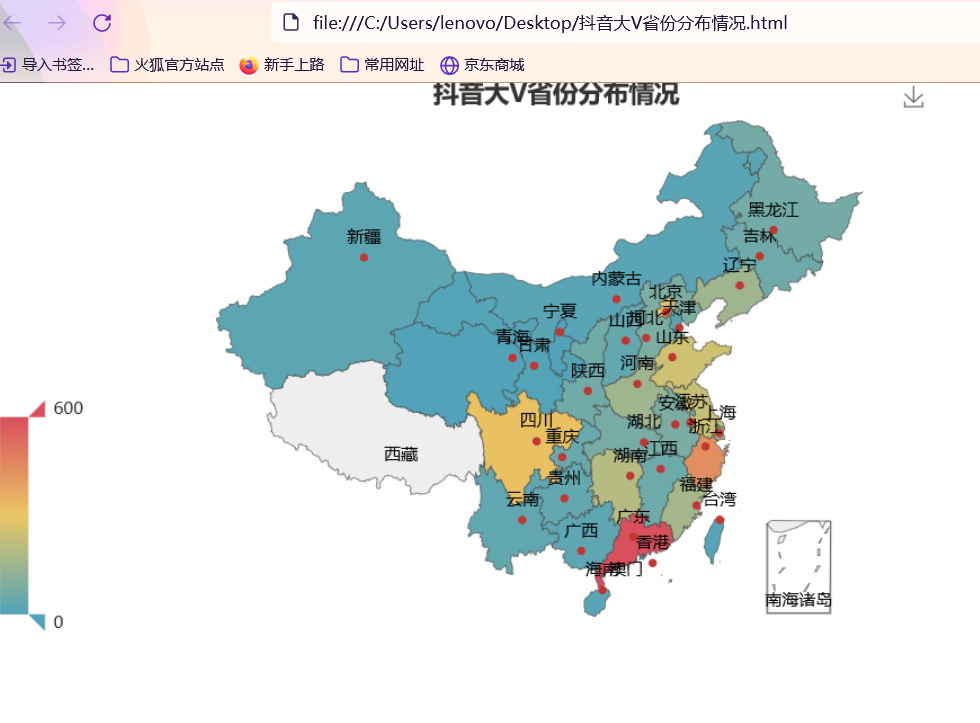
本实例支付的费用只是购买源码的费用,如有疑问欢迎在文末留言交流,如需作者在线代码指导、定制等,在作者开启付费服务后,可以点击“购买服务”进行实时联系,请知悉,谢谢
感谢
3
手机上随时阅读、收藏该文章 ?请扫下方二维码
相似例子推荐
评论
作者
掌勺
购买服务
购买服务
服务描述:
在我的例子中,有任何问题可以联系我QQ
服务价格:
¥15
我要联系
4
例子数量
2
帮助
15
感谢
评分详细
可运行:
4.5
分
代码质量:
4.5
分
文章描述详细:
4.5
分
代码注释:
4.5
分
综合:
4.5
分
作者例子
Python自动化爬取天气预报、疫情、糗事、通过企业微信发送给男女朋友
python开发幸运水果抽奖大转盘
python模拟登入某平台+破解验证码
Python实现抖音各类型数据可视化




